Tags
MongoDB offers a free MOOC, M220JS for Javascript developers. This page aims to keep study notes through the course. Used code snippets are taken from course repository. M220js aims to provide introduction to MongoDB with usage from Node.js application as backend. Through preparing database connection of application;
- Creation and sharing of database connections
- Writing data with different levels of durability
- Handling errors from driver
topics are investigated. Application uses Nodejs, Express, MongoDB and React.
Through Atlas, create a new project M220 and free tier cluster of mflix

mflix-js application provides a skeleton with change requirements mostly in database access objects (src/dao)
- src/dao/usersDAO.js
- src/dao/moviesDAO.js
- src/dao/commentsDAO.js
Used in environment;
npm packet manager will be used in development cycle
- npm install
- mpm start
- npm test -t mongoclient
The application api layer uses port 5000 by default
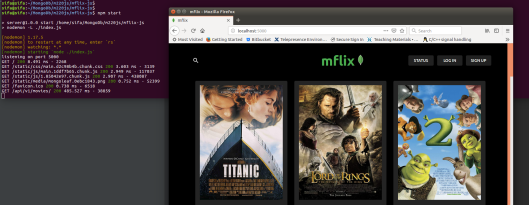

uploading data to cluster through mongorestore
sifa@sifa:~/MongoDb/m220js/mflix-js$ mongorestore --drop --gzip --uri "mongodb+srv://:@m.mongodb.net/test?retryWrites=true" data
Callbacks, promises, asynchronous waits
This section is devoted to how driver is used in asynchronous programming. A good introduction may be helpful for js beginners like me. The relevant test is test/lessons/callbacks-promises-async.spec.js.
findOne(query, options, callback) -> {Promise}
When there is no provided callback, a promise is returned. Await statements should be wrapped with a try/catch block. And to use await, the enclosing function should be async.
callback:
movies.findOne({ title: "Once Upon a Time in Mexico" }, function(err, doc) {
expect(err).toBeNull()
expect(doc.title).toBe("Once Upon a Time in Mexico")
expect(doc.cast).toContain("Salma Hayek")
done()
})
promise:
movies
.findOne({ title: "Once Upon a Time in Mexico" })
.then(doc => {
expect(doc.title).toBe("Once Upon a Time in Mexico")
expect(doc.cast).toContain("Salma Hayek")
done()
})
.catch(err => {
expect(err).toBeNull()
done()
})
asynchronous wait:
try {
let { title } = await movies.findOne({
title: "Once Upon a Time in Mexico",
})
let { cast } = await movies.findOne({
title: "Once Upon a Time in Mexico",
})
expect(title).toBe("Once Upon a Time in Mexico")
expect(cast).toContain("Salma Hayek")
} catch (e) {
expect(e).toBeNull()
}
Basic Reads
findOne() method returns a single document as result. It involves querying a unique index _id field.
let result = await movies.findOne({ cast: filter })
expect(result).not.toBeNull()
Projection usage is a little bit different than the mongo shell as, we have to specify projection as json object {projection: {}}. _id field is on by default so it should be explicitly removed from projection if not wanted.
let result2 = await movies.findOne(
{ cast: filter },
{ projection: { title: 1, year: 1, _id: 0 } },
)
expect(result).not.toBeNull(
find() method returns an iterator, which should be iterated further by next().
let result = await movies.find({
cast: { $all: ["Salma Hayek", "Johnny Depp"] },
})
expect(result).not.toBeNull()
let { title, year, cast } = await result.next()
expect(title).toBe("Once Upon a Time in Mexico")
To make a query about countries and return title, a simple solution will be:
cursor = await movies.find({countries: {$in: countries}}, { projection: {title: 1 }})

Chapter #2 User-Facing Backend
Cursor methods and aggregation equivalents
We can limit the number of documents that cursor will iterate with
const limitedCursor = movies
.find({ directors: "Sam Raimi" }, { _id: 0, title: 1, cast: 1 })
.limit(2)
expect((await limitedCursor.toArray()).length).toEqual(2)
Its aggregation equivalent will be as:
const limitPipeline = [
{ $match: { directors: "Sam Raimi" } },
{ $project: { _id: 0, title: 1, cast: 1 } },
{ $limit: 2 },
]
const limitedAggregation = await movies.aggregate(limitPipeline)
expect((await limitedAggregation.toArray()).length).toEqual(2)
Sorting documents (in ascending order)
const sortedCursor = movies
.find({ directors: "Sam Raimi" }, { _id: 0, year: 1, title: 1, cast: 1 })
.sort([["year", 1]])
const movieArray = await sortedCursor.toArray()
const sortPipeline = [
{ $match: { directors: "Sam Raimi" } },
{ $project: { _id: 0, year: 1, title: 1, cast: 1 } },
{ $sort: { year: 1 } },
]
const sortAggregation = await movies.aggregate(sortPipeline)
const movieArray = await sortAggregation.toArray()
skipping documents
skipping documents makes sense when the query is sorted. Otherwise it wont make sense. For example, if we want to skip the first five oldest movies;
const skippedCursor = movies
.find({ directors: "Sam Raimi" }, { _id: 0, year: 1, title: 1, cast: 1 })
.sort([["year", 1]])
.skip(5)
const skippedPipeline = [
{ $match: { directors: "Sam Raimi" } },
{ $project: { _id: 0, year: 1, title: 1, cast: 1 } },
{ $sort: { year: 1 } },
{ $skip: 5 },
]
Sorting, skipping and limiting functionalities can be aggregated to form complex queries like paging. For example, if it is desired to page data;
let { query = {}, project = {}, sort = DEFAULT_SORT } = queryParams
let cursor = await movies.find(query).project(project).sort(sort)
let itemsThatShouldBeSkipped = page*moviesPerPage
const displayCursor = cursor.skip(itemsThatShouldBeSkipped).limit(moviesPerPage)
Aggregation
Aggregation is a pipeline that are composed of one or more stages, each stage use one or more expressions and expressions are functions responsible from a basic work in transforming data. {“$add”: [“$a”, “$b”]}
An example pipeline will be $match, $project, $group pipeline
$match: {directors: “Sam Raimi”}
$project: {_id: 0, title: 1, rating: 1}
$group: {_id: 0, avg_rating: {“$avg”: “imdb.rating”}}
Basic write operations
inserting documents may be done with insertOne and insertMany. trying to dublicate _id will fail. As an alternate to inserting, we can specify an upsert in an update operation
inserting one document:
let insertResult = await videoGames.insertOne({
title: "Fortnite",
year: 2018,
})
let { n, ok } = insertResult.result
expect({ n, ok }).toEqual({ n: 1, ok: 1 })
expect(insertResult.insertedCount).toBe(1)
expect(insertResult.insertedId).not.toBeUndefined()
updateOne() may also be used with {upsert: true} specified in options. Then we will look if document is already present update so, otherwise insert a brand new document
let upsertResult = await videoGames.updateOne(
// this is the "query" portion of the update
{ title: "Call of Duty" },
// this is the update
{
$set: {
title: "Call of Duty",
year: 2003,
},
},
// this is the options document. We've specified upsert: true, so if the
// query doesn't find a document to update, it will be written instead as
// a new document
{ upsert: true },
)
Write Concerns
Write concerns is about how much to be sure a write request is propagated to all nodes in cluster. Default writeConcern: {w: 1} only requests an acknowledgement that one node applied the write.
If we want primary wait for majority of nodes to replicate the data before providing an acknowledgement, we can use {w: majority}. Notice that it takes more time than {w: 1} due to replication lag but mode durable to ensure vital writes are majority committed.
There is also a fire & forget {w: 0} that does not request an acknowledgement, which is fastest but obviously least durable. An example may be an IoT device sending non vital frequent data, if loosing some wont be a problem.
In a 3 node MongoDB replica set, valid writeConcerns will be:
- {w: 0}
- {w: 1}
- {w: majority}

Basic Updates
Two operations for updating are updateOne() and updateMany(). Notice that updateOne() will update the first document that it finds in the collection.
Joins
joins are used to combine collections of data $lookup. Compass may be used to create aggregations and then exporting into applications native language (node, java, python3, c#).
$match {year: {“$gte” : 1980, “$lt”: 1990}}
$lookup {from: “comments”, let: {“id”: “$_id”}, pipeline : [{“match”: {“$expr”: {“$eq”: [“$movie_id”: “$$id”]}}}, {“$count” : “count”}], as: “movie_comments”}
from field is joining from. let allows us to declare variables in pipeline, referring to document fields in our source collection. At the end we will have movie_comments array that will have all comments of the movie


Basic Deletes
deleteOne() / delteMany() performs delete counterpart of updateOne() / updateMany(). They change collection data, update indexes and corresponding entries will be added to oplog. Oplog is responsible from replication inside replica set. Remember that deleteOne() will delete the first document it finds in natural order (order in which documents were inserted). deleteMany() deletes all documents that meet predicate.
Chapter #3 Admin Backend
This chapter covers topics:
- read concerns
- join collections using expressive $lookup
- perform bulk operations
- clean data
Read concerns
Relates to getting sure on how many nodes are involved in db operation before getting an acknowledgement. Read concerns represents different level of isolation about consistent view of the database, and how consistent we would like the nodes to be. There may appear instances where a data is tried to read without being written to all nodes in db.
By default, MongoDB will use {readConcern : local}, which means that we are only sure that it is written to the primary node. There is a slim chance that, the this read data, may be rolled back due to replication issues into secondaries. In most of the cases this will be fine. However, a higher level of consistency may be achieved by {readConcern: majority}. In this case it is mission critical and we are sure that data read will not be rolled back.
As an example counting the number of comments of a user and getting the most commented 20 of the user emails, following query pipeline may be applied;
let group = {"$group" : {_id: "$email", count:{$sum: 1}}}
let sort = {$sort: {count: -1}}
let limit = {$limit: 20}
const pipeline = [group, sort, limit]
// TODO Ticket: User Report
// Use a more durable Read Concern here to make sure this data is not stale.
const readConcern = {readConcern: {level: "majority"}}
const aggregateResult = await comments.aggregate(pipeline, {
readConcern,
})

Bulk writes
Bulk writes are used to batch a series of write operations into a container (list or array or …, which is implementation detail) send this, and get one acknowledgement to gain efficiency in transport.
Ordered bulk write is the default setting for bulk writes in MongoDB. Executes writes sequentially and will end execution after first write failure. This default action may be overriden with flag {ordered: false}. To make write operations non blocking and overall write parallel, use on ordered bulk write as;
db.someCollection.bulkWrite({{updateOne: {}}, {updateOne: {}}}, {ordered: false})
These individual writes may fail in their own but this will not stop overall operation.

Chapter #4 Resiliency
Chapter is devoted to application resiliency, robustness.
Connection Pooling
Connection pooling is about reusing database connections. Establishing database connection takes time and resources, and if there is possibility of subsequent requests, it may be better to use connections as a pool, rather than creating and destructing per need. After initial connection, subsequent requests appear faster. Default size of pool is 100. A large influx of operations can be handled more quickly with a pool of existing connections. Besides, new operations can be serviced with preexisting connections, so a new connection does not need to be created each time.

Robust Client Configuration
It is better to always specify a wtimeout with majority writes. If external resources, like network have problems, and if we wait too long for {w: majority} due to external resource problems, we may find ourselves into bottleneck due to acknowledgement latency. Specifying a timeout will make sure, the acknowledgements are not waited more than a preset value. {w: “majority”, wtimeout: 5000} will let 5 second for write acknowledgements. Besides for a server connection, {serverSelectionTimeout: 5} may be used and handled which defaults to 30 seconds. Timeout has no value in read ops & read majority choices.
Writes with Error Handling
Errors are results of nature. Distributed systems are prone to network errors, concurrent systems are prone to duplicate key errors. Duplicate key error occurs when we try to insert a document (_id) in place of already existing one. Result will reveal itself by E11000 duplicate key error. Best action may be creating a new key (_id) and retry the write. Timeout errors are best to be handled by increasing timeout or reducing durability guarantee (reduce writeConcern} if possible. WriteConcernError occurs when we demand a durability that can not be satisfied by the cluster. If replica set has 3 nodes, { writeConcern : 5 } can not be satisfied and produce a writeConcernError. For all these, a try / catch may be used to handle error.
Principle of Least Privilege
Every program and every privileged user of system should operate using the least amount of privilege necessary to complete the job.
Some operational examples:
1.
Assume a election collection as;
{ year: 1828, winner: "Andrew Jackson", winner_running_mate: "John C. Calhoun", winner_party: "Democratic", winner_electoral_votes: 178, total_electoral_votes: 261 }
Here total_electoral_votes represents the total number of electoral votes that year, and winner_electoral_votes represents the number of electoral votes received by the winning candidates.
To retrieve all the Republican winners with at least 160 electoral votes we can use the following query;
elections.find( { winner_party: "Republican", winner_electoral_votes: { "$gte": 160 } } )
2.
Assuming a phone firmware collection as;
{ model: 5, date_issued : Date("2014-03-04T14:23:43.123Z"), software_version: 3.7, needs_to_update: true }
Write an update query that will make needs_to_update field true for documents that have version older than 4.0 ;
phones.updateMany( { software_version: { "$lt": 4.0 } }, { "$set": { needs_to_update: true } } )
3.
For a collection like:
{ name: "Ada", height: 1.7 }
Write a query that will find only the 4th- and 5th-tallest people in the people_heights collection?
people_heights.find().sort({ height: -1 }).skip(3).limit(2)