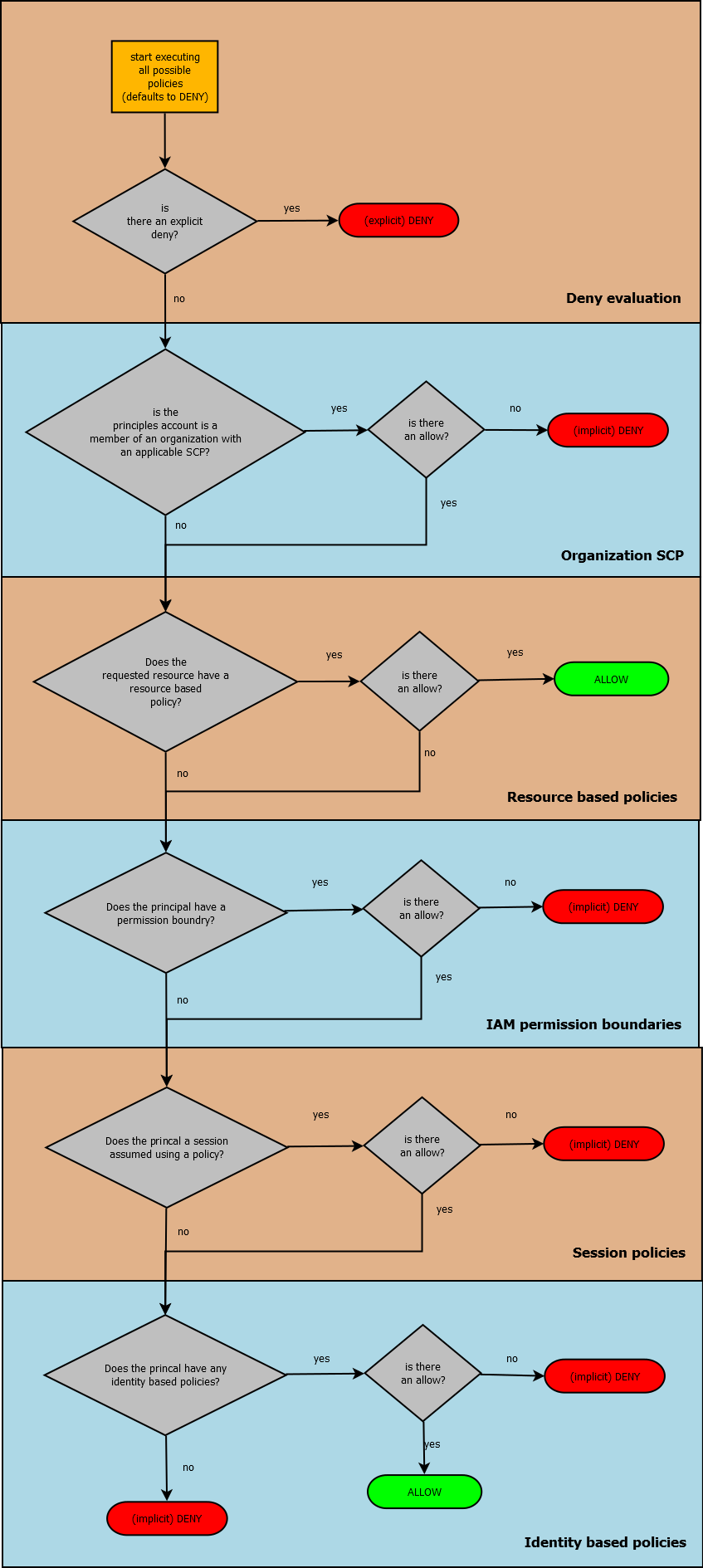
What is a container?
Linux containers are normal processes that are using namespace & cgroup features of kernel. With these, containers are able to have isolated namespaces and resource limits. By default, docker creates a set of hostname, process ids, file system, network interfaces and ipc stack for the container that is running.

Containers, specified by Open Containers Initiative, run on an host operating system and get low level networking primitives through host OS.
Some basics and running a test container
Before starting to dive deep, lets have a setup. The basic docker objects are images, containers, networks and volumes. The docker system prune -a command will help removing all stopped containers, dangling images, images without a running container and unused networks, and provide somewhat clean environment.
docker system prune -a

docker inspect will provide information about a docker resource. Lets inspect an handy alpine image.
docker pull alpine:latest
docker inspect alpine:latest > alpine-inspect.txt

Resulting alpine-inspect.txt will be similar to

Here we see two configurations, ContainerConfig & Config. What is the difference? Config contains the image’s information. Besides, ContainerConfig shows the details of the container that was used to build the last layer of the image. The new container that will be created from the image with docker run\create will apply the data of Config.
Good. For alpine container, entrance will be through “Cmd”: [“/bin/sh”] & “Entrypoint”: null. There is a good article for Cmd & Entrypoint difference. As a summary, CMD defines default commands and parameters (or if an ENTRYPOINT is present, parameters that would be added) for a container. CMD is an instruction that is best to use if you need a default command which users can easily override. ENTRYPOINT is preferred when you want to define a container with a specific executable. You can override an ENTRYPOINT when starting a container with the –entrypoint flag.
For alpine, there is no ENTRYPOINT but CMD of “/bin/sh”, which makes sense as being a base image. Lets do something and try to get network interfaces of alpine.
we can override the default command and get the network interfaces through
docker run alpine ip add

or use the default CMD and attach to the shell with -it option
docker run -it alpine

Now, a question may arise about eth0, what is it and where does it come from?
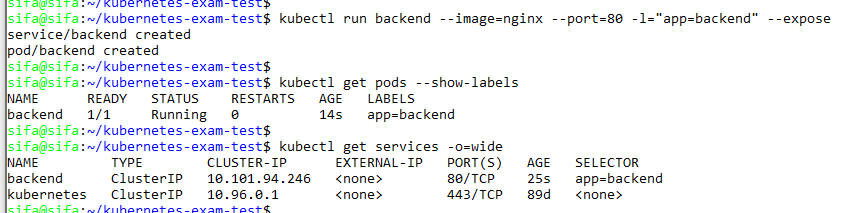
Single Host Containers – bridge networking
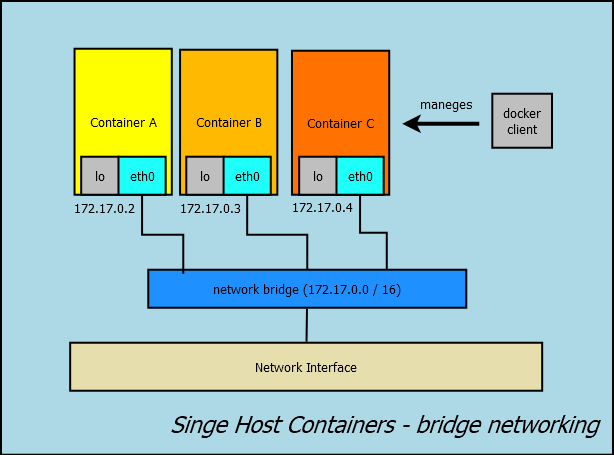
In the previous section, we run a single host alpine container. Since we did not specified a network preference, default bridge network is used. In this configuration, docker will create a bridge in host, and guest running in bridge mode would have an interface connected to this bridge. Therefore they would have an isolated network inside the host. Container in the same host can talk with each other through this bridge, and default route in host will enable the container to reach outside.
Lets start two alpine containers and have a look
docker run --net=bridge -it alpine
we see that containers take ip from 172.17.0.0/16 range, and can ping each other.

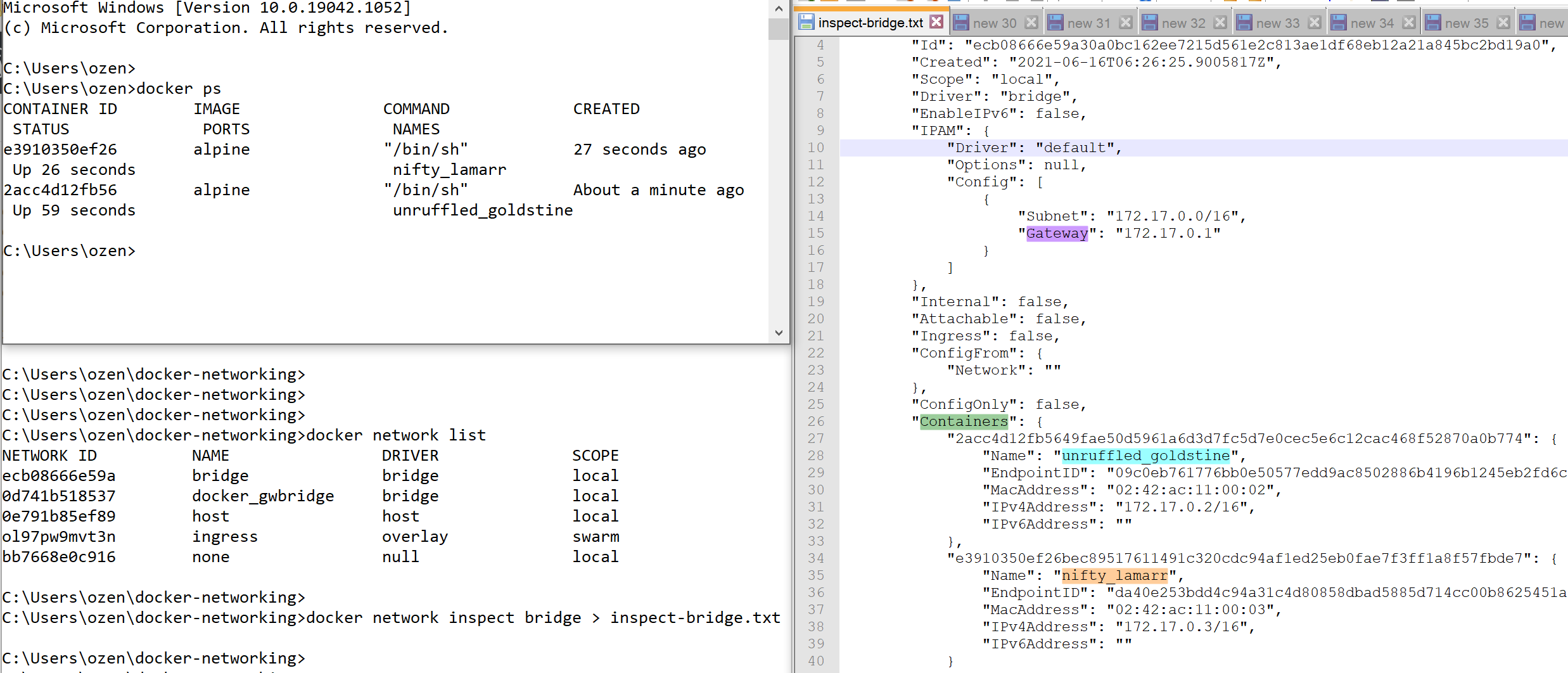
Looking at the host network resources, we see that there is a bridge that connects these container interfaces.
docker network list
docker network inspect bridge
Single Host Containers – host networking
When we do not want to isolate the guest containers but actually use the network namespace of the host, –net=host can be used to switch into host networking mode. Guest container will share network resources whatever host already have, much like any other process running in the host.

docker run –net=host -it alpine
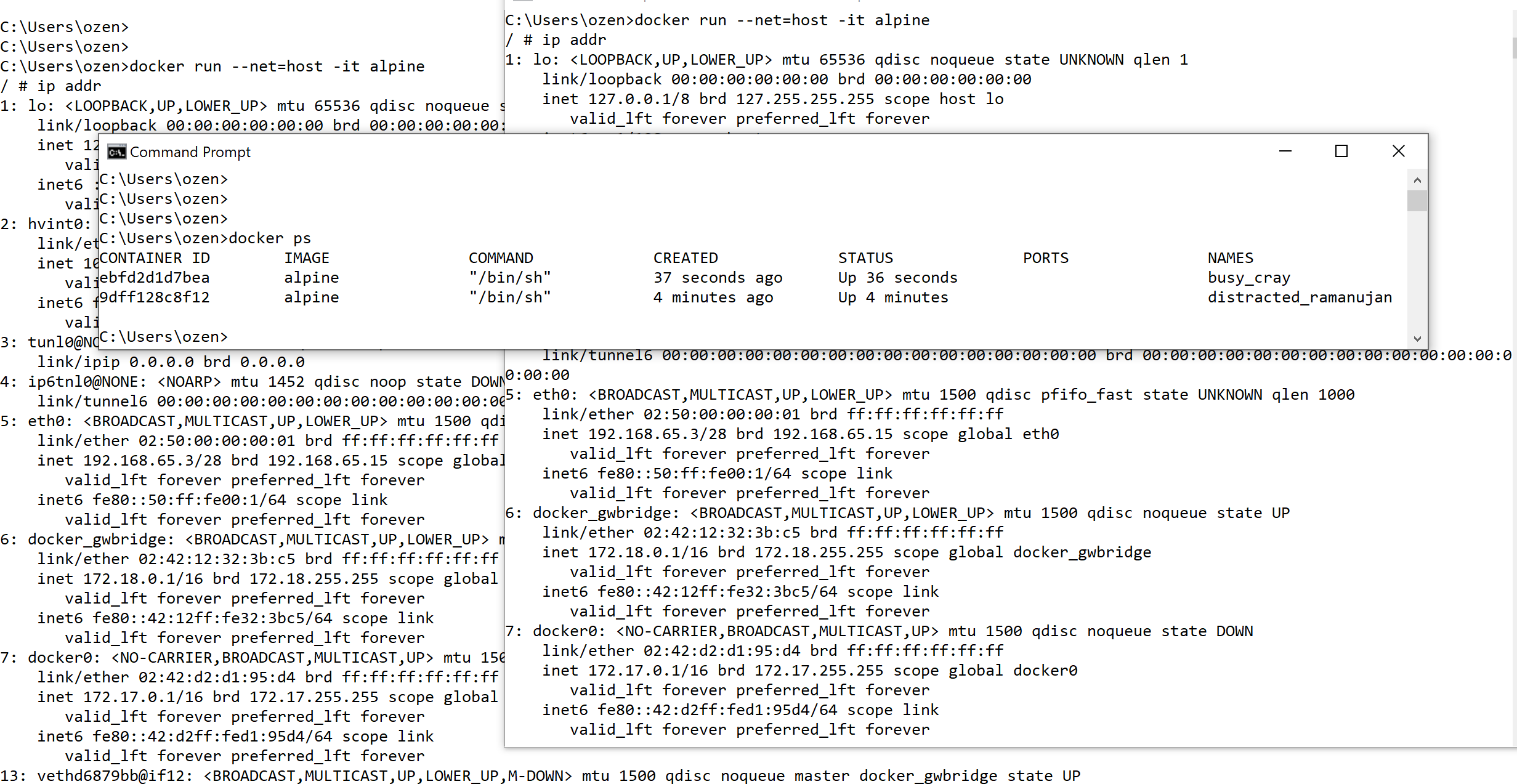
This mode has the advantage of removing redirection and increasing network speed. The disadvantage is, it increases attack surface with using host network namespace.
Single Host Containers – container networking
Container networking enables network namespace sharing between containers without touching host. Kubernetes uses this mode for containers in the pod.

Assuming we have a container ,
docker run --name=base --net=bridge -it alpine
we can start another container with the same network namespace of an already existing one
docker run --net=container:base -t alpine

resulting bridge network will contain one container entry as expected

Similar to using a peer containers network namespace, we can share its ipc or pid space as well, like
docker run --name alpine --net=container:nginx --ipc=container:nginx --pid=container:nginx -it alpine
Single Host Containers – no networking
This mode makes containers have their own namespace, isolated by default. This is the use case when no network communication is needed. Besides, it allows custom network setup, if needed.
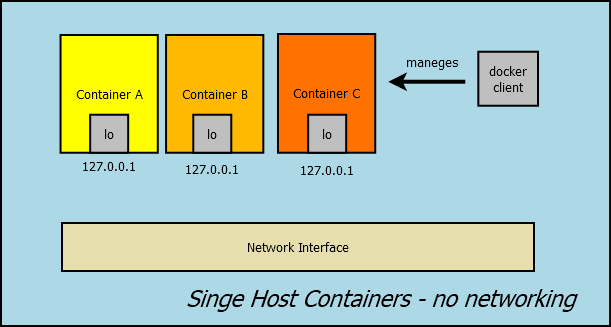
docker run --net=none -it alpine
As a result, he container will only have loopback

Network Security- icc / ip_forward / iptables
By default, inter-container communication is enabled (–icc=true), allowing containers to talk with each other without any restrictions. Moreover, –ip_forward and –iptables flags tune communication between containers and the environment.
Multi Host Containers
For multi host containers, assigning IP addresses to containers is a problem to solve. It can be solved through Overlay Networks, where an orthogonal, practically hidden networking layer is spawned, distributed over different hosts. docker_gwbridge & ingress network resources perform overlaying.

Besides, with Linux kernel version 3.19 IPVLAN feature is introduced. Each container of the host gets a unique and routable IP address. IPVLAN takes a single network interface and creates multiple virtual network interfaces with different MAC addresses assigned to them, which can be used in containers.
Container Network Interface
CNI is a plugin based networking specification and library suite for Linux containers. Using its config file CNI uses plugins to add or remove containers from network. For CNI internals, there is an excellent blog post from Langemak.

Kubernetes Networking
Kubernetes networking primitives are;
- Containers can communicate with all other containers without network address translation.
- Nodes can communicate with all containers (and vice versa) without network address translation.
- The IP a container is same for himself and others.
- Containers of the same pod share the same network namespace, so can talk with each other on localhost.
- Pods should have an IP address of a flat networking namespace with connection to other nodes and pods.
- External traffic can be routed to pods through ingress, pods can reach external APIs through egress rules.
When the pod is spinned, an infrastructure container (pause container) ramps up in bridge mode that will get the pods ip and create network namespace. All other containers are initialized with container networking with this infrastructure container to share the same network namespace. As the containers share the same port range, it is developers responsibility to avoid collusions.
Kubernetes Pods have routable ip which can be used inter pod communication, however, as pods are ephemeral, it is better to use service ips, that are stable and can be resolved through DNS.
Kubernetes uses flat ip space, whereas docker containers have ip in the range 172.x.x.x range. If the container connect to any other one, the observed ip address will be different. For this reason (since self seen ip and observed ip is different), docker containers can not self register themselves to any service.
Pod declarations allow specifying the containers and Kubernetes automates setting up corresponding namespaces and cgroups. Pod containers will use their own cgroups but may share hostname, pid, network and ipc spaces. For example,
Start with a base container that will initialize namespaces
docker run -d --name base -p 8080:80 gcr.io/google_containers/pause-amd64:3.0
then share this base containers network, pid and ipc namespaces as
docker run --name alpine --net=container:base --ipc=container:base --pid=container:base -it alpine
With this setup, each container thinks that they are running on the same machine. They can talk to each other on localhost, they can use shared volumes and they can use IPC or send each other signals like HUP or TERM.
Usual parent and keep alive container of a pod that initialize network and other resources is “pause” container. Other containers of the pod shares the same network namespace. when we look at running containers of a kubernetes node, we will see many “pause” containers that are hidden.

Pause container assumes the role of PID 1 and will reap any zombies by calling wait on them when they are orphaned by their parent processes. The code is surprisingly simple;
/*
Copyright 2016 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
static void sigdown(int signo) {
psignal(signo, "Shutting down, got signal");
exit(0);
}
static void sigreap(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0);
}
int main() {
if (getpid() != 1)
/* Not an error because pause sees use outside of infra containers. */
fprintf(stderr, "Warning: pause should be the first process\n");
if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 1;
if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 2;
if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,
.sa_flags = SA_NOCLDSTOP},
NULL) < 0)
return 3;
for (;;)
pause();
fprintf(stderr, "Error: infinite loop terminated\n");
return 42;
}
But how can we achieve this namespace sharing?
In Linux new process inherits namespaces from the parent process. The way to have own namespaces is through unshare system call. An example of a ramping a shell in new PID, UTS, IPC, and mount namespaces is through
sudo unshare --pid --uts --ipc --mount -f chroot rootfs /bin/sh
The new processes can be added to previous namespace through setns system call.
Process creation
A sample process creation is through fork(), that creates a copy of the parent process, and exec() that changes the executable. Linux threads are lightweight processes, that differ in memory allocation, as they share text, data and heap. Usually programming languages will provide a wrapper function to ease these. Each process will have its entry in the process table that also keeps the process state and exit code. After a child process finishes running, its process table entry remains intact till parent queries its exit code through wait() syscall. What happens if parent does not wait(), or crashes in between? In this case, the child may become zombie. Zombie processes are the ones that have stopped running but their process table entry still exists because the parent did not wait() ed or there is no running parent at all.
When a process’s parent dies before the child, kernel assigns the child process to the “init” process (process with PID 1). The init process becomes the parent meaning that it should wait() the adopted process to get its exit code to avoid it become a zombie.
With Docker, each container usually has its own PID namespace and the ENTRYPOINT process is the init process, and expected to handle this responsibility. Luckly, If the container is not a general purpose base container it wont have forks() and this wont be problem.
References
Container networking from Docker to Kubernetes
What are Kubernetes Pods Anyway?
The Almighty Pause Container